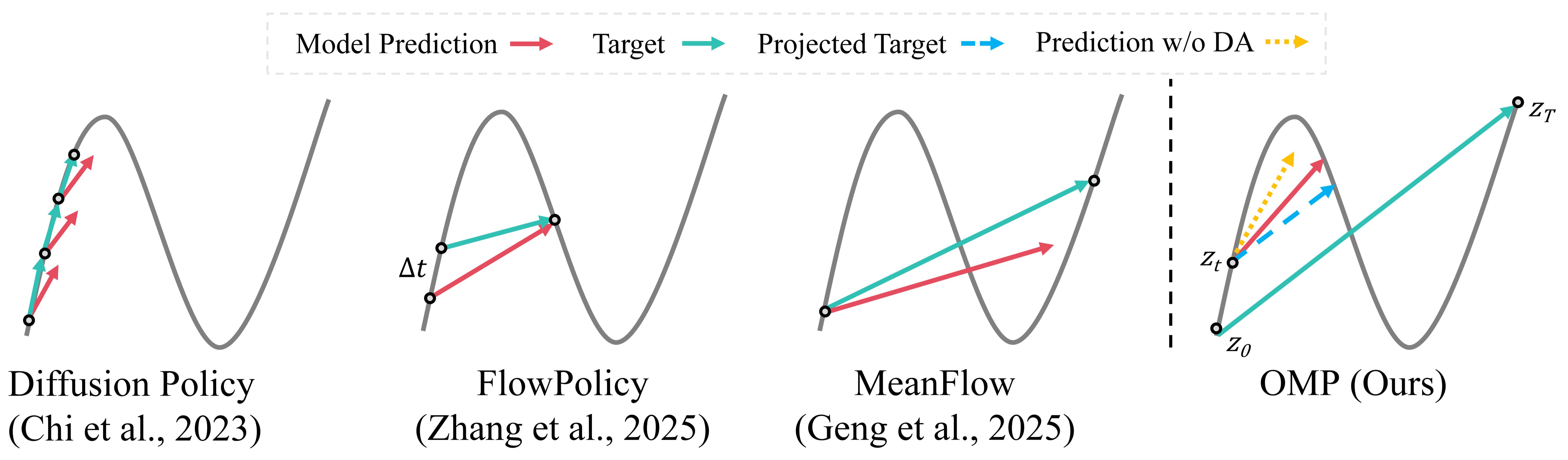
Robot manipulation has increasingly adopted data-driven generative policy frameworks, yet the field faces a persistent trade-off: diffusion models suffer from high inference latency, while flow-based methods often require complex architectural constraints. Although in image generation domain, the MeanFlow paradigm offers a path to single-step inference, its direct application to robotics is impeded by critical theoretical pathologies, specifically spectral bias and gradient starvation in low-velocity regimes. To overcome these limitations, we propose the One-step MeanFlow Policy (OMP), a novel framework designed for high-fidelity, real-time manipulation. We introduce a lightweight directional alignment mechanism to explicitly synchronize predicted velocities with true mean velocities. Furthermore, we implement a Differential Derivation Equation (DDE) to approximate the Jacobian-Vector Product (JVP) operator, which decouples forward and backward passes to significantly reduce memory complexity. Extensive experiments on the Adroit and Meta-World benchmarks demonstrate that OMP outperforms state-of-the-art methods in success rate and trajectory accuracy, particularly in high-precision tasks, while retaining the efficiency of single-step generation.
@article{fang2026omp,
title={OMP: One-step Meanflow Policy with Directional Alignment},
author={Han Fang and Yize Huang and Yuheng Zhao and Paul Weng and Xiao Li and Yutong Ban},
journal={arXiv preprint arXiv:2512.19347},
year={2026},
url={https://arxiv.org/abs/2512.19347}
}