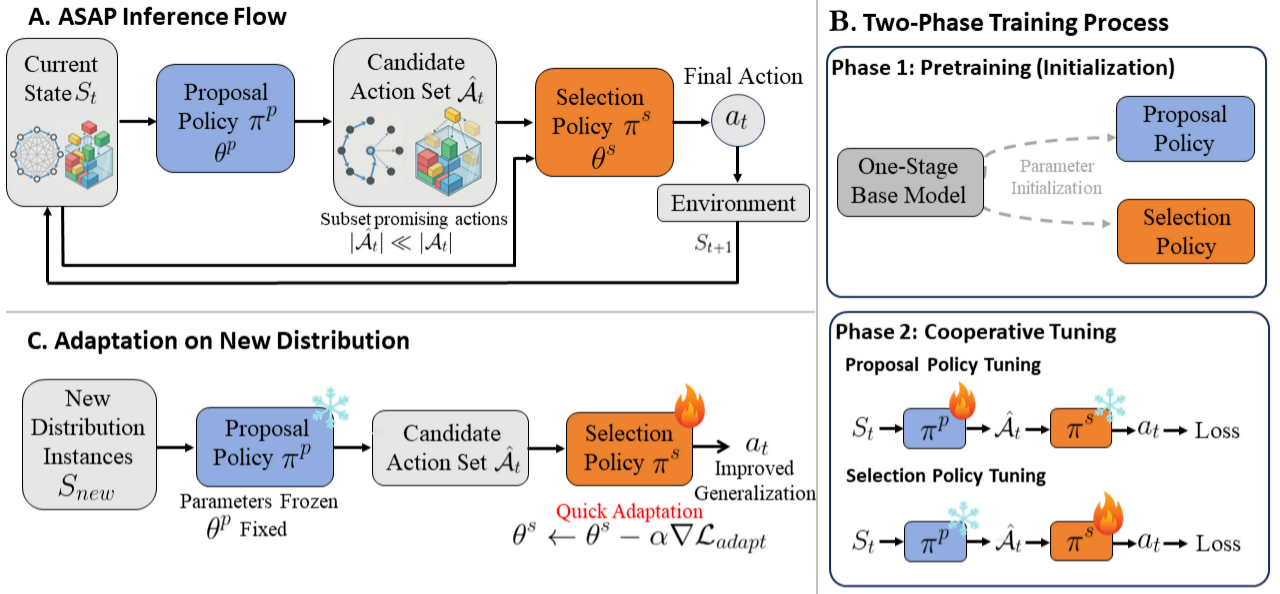
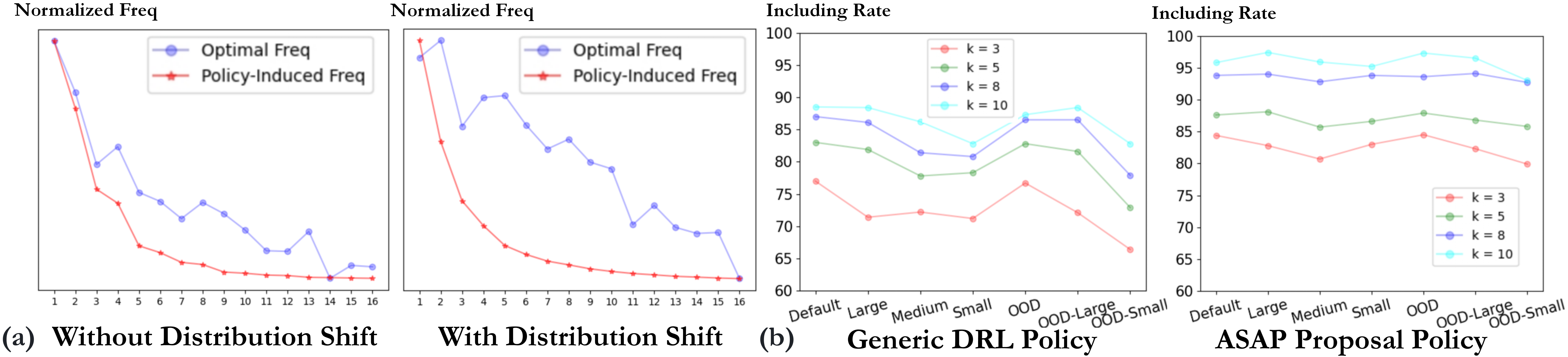
Deep Reinforcement Learning (DRL) has emerged as a promising approach for solving Combinatorial Optimization (CO) problems, such as the 3D Bin Packing Problem (3D-BPP), Traveling Salesman Problem (TSP), or Vehicle Routing Problem (VRP), but these neural solvers often exhibit brittleness when facing distribution shifts. To address this issue, we uncover the Satisficing Generalization Edge, which we validate both theoretically and experimentally: identifying a set of promising actions is inherently more generalizable than selecting the single optimal action. To exploit this property, we propose Adaptive Selection After Proposal (ASAP), a generic framework that decomposes the decision-making process into two distinct phases: a proposal policy that acts as a robust filter, and a selection policy as an adaptable decision maker. This architecture enables a highly effective online adaptation strategy where the selection policy can be rapidly fine-tuned on a new distribution. Concretely, we introduce a two-phase training framework enhanced by Model-Agnostic Meta-Learning (MAML) to prime the model for fast adaptation. Extensive experiments on 3D-BPP, TSP, and CVRP demonstrate that ASAP improves the generalization capability of state-of-the-art baselines and achieves superior online adaptation on out-of-distribution instances.